Debug 故事 01

警告:为方便阅读,本文部分代码实为伪代码,请勿当真。
背景
最近我用 espnet 跑了一个比较慢的基线实验,采用 SNR loss 进行训练,虽然用上了单机 4 卡(2080ti)依然需要一周左右的时间才能完成。在基线的基础上,我希望调整一下模型训练过程,以便进行后续拓展:
- 在计算 SNR loss 前对当前 batch 的标签进行判断,如果存在全零项,就用 L1 loss 函数来代替,因为 SNR loss 在标签为全零时无法计算。
于是,我对原先的 loss 计算代码
loss, stats = 0.0, {}
...
loss_ = snr_loss(speech_ref, speech_pre)
stats_ = {"snr_loss": loss_}
loss += loss_
stats.update(stats_)
做了如下修改:
loss, stats = 0.0, {}
...
has_all_zero = torch.cat(speech_ref, dim=0).sum(dim=-1).eq(0).any()
if has_all_zero:
loss_ = l1_loss(speech_ref, speech_pre)
stats_ = {"l1_loss": loss_}
else:
loss_ = snr_loss(speech_ref, speech_pre)
stats_ = {"snr_loss": loss_}
loss += loss_
stats.update(stats_)
Bug?
上面的修改看似应该没有任何问题,于是我开始了模型训练。然而在检查模型的训练日志时,我发现了一个令人震惊的事实,那就是日志显示模型的 l1_loss 始终都是负的!这在理论上是绝不可能的,因为 L1 loss 是绝对值。
Debug
考虑到日志显示的结果是对若干步训练结果的平均(1 个 iteration 大概包括 100 个 batch),于是我首先在上面修改的代码中插入了 print 语句来检验每个具体 batch 计算出的 L1 loss。结果也如预期般的正常,每一个打印出来的 L1 loss 值都是正的。这就与日志中的结果相矛盾了。

此时我心中有一个巨大的疑惑:后续的代码中难道有任何操作会修改 stats 中的 loss 值吗?
乍一看似乎找不到这种操作,我只好从写日志的函数着手开始分析。因为最终写到训练日志中的 l1_loss 是不正常的,如果写日志的函数的输入输出值对应不上的话,很有可能就是它的问题!

经过一番跳转可以找到,espnet 中模型训练的日志是通过类别 Reporter 的对象来输出的,它的 log_message 方法就是用来生成写到文件的日志信息。于是我在其中插入了一些 print 语句来探查输入的原始数据的值,得到的是如下的一串数字的列表:
l1_loss=[WeightedAverage(value=nan, weight=0), WeightedAverage(value=-0.835070
788860321,weight=8), WeightedAverage(value=0.017597751691937447, weight=8),
WeightedAverage(value=nan, weight=0), WeightedAverage(value=nan, weight=0),
WeightedAverage(value=nan, weight=0), WeightedAverage(value=nan, weight=0),
WeightedAverage(value=-1.290090799331665, weight=8), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=nan, weight=0), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=nan, weight=0), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=nan, weight=0), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=nan, weight=0), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=nan, weight=0), WeightedAverage(value=
nan, weight=0), WeightedAverage(value=-0.5981062650680542, weight=8),
...
WeightedAverage(value=0.014390362426638603, weight=8)]
列表里的每个 WeightedAverage 对象的 value 就对应着一个 batch 内算出的 loss 平均值,weight 则代表该 batch 的 loss 权重(实际上等于 batch_size)。
最终日志输出的 l1_loss 标量值就是这些列表元素按各自权重的加权和,如果遇到 loss 值是 nan 则跳过。
列表里的那些权重为 0 的 nan 值实际上是代码添加的,目的是将 stats 字典的所有 key 对应的 value(都是列表)长度补齐到等长,即保证每个 batch 都有与之对应的一项数值。
从上面的例子可以看出,日志系统在拿到“原始数据”的时候看到的已经是有正有负的 L1 loss 值了,因此 bug 应该在这一步之前就已经出现。

那么,究竟是哪一步操作导致 stats 中的 l1_loss 如此奇怪呢?
(其实原因早已经在前文中提到了……在继续往下翻之前,你不妨大胆猜想一下)
检查完了 loss 计算和写日志的代码,夹在它们中间的就只剩一些零碎的操作了,比如反向传播、优化器迭代、学习率调整等等。这些显然和 stats 的修改没有关系。
难道遗漏了什么?为了不错过任何一点蛛丝马迹,我打算从 loss 计算结束开始,逐行进行调查。很快啊,一个以 stats 作为输入和输出的函数引起了我的注意。
if ngpu > 1 or distributed:
# Apply weighted averaging for loss and stats
loss = (loss * weight.type(loss.dtype)).sum()
# if distributed, this method can also apply all_reduce()
stats, weight = recursive_average(stats, weight, distributed)
# Now weight is summation over all workers
loss /= weight
这个 recursive_average 函数的特别之处在于,它的最后一个参数 distributed 意味着它和多机/多卡的运行环境有着紧密关系。
进一步跳转到它的定义
def recursive_average(obj, weight: torch.Tensor, distributed: bool = False):
obj = recursive_sum(obj, weight, distributed)
weight = weight.sum()
if distributed:
torch.distributed.all_reduce(weight, op=ReduceOp.SUM)
# Normalize weight to be sum-to-1
obj = recursive_divide(obj, weight)
return obj, weight
就可以看到它的功能是对 stats 中所有的 value 列表的每一个元素都进行某种平均。可是对一个标量元素取平均有什么意义?

这个函数针对的场景如果是多机/多卡的话……
看着 recursive_average, recursive_sum, recursive_divide 函数中都出现的 torch.distributed.all_reduce 函数,我突然意识到,这些操作其实是对不同 GPU 上的对应数据(loss 值)进行聚合,那么平均就具有意义了。
同时,看到 all_reduce 这个熟悉的名词,我不禁回想起三年前《并行计算与并行算法》这门课上的学到的一些概念……我开始有了一些想法。
为了验证这个想法,我首先把实验设置换成了单卡,重新开始一次训练。几分钟后,我打开日志文件瞧了瞧,果然所有的 l1_loss 都恢复成了预期的正值。
有了实验的验证,我开始按照新的想法修改起最初的代码:
loss, stats = 0.0, {}
...
has_all_zero = torch.cat(speech_ref, dim=0).sum(dim=-1).eq(0).any()
if has_all_zero:
loss_l1 = l1_loss(speech_ref, speech_pre)
loss_snr = loss_l1.new_zeros(())
stats_ = {"l1_loss": loss_l1, "snr_loss": loss_snr}
else:
loss_snr = snr_loss(speech_ref, speech_pre)
loss_l1 = loss_snr.new_zeros(())
stats_ = {"l1_loss": loss_l1, "snr_loss": loss_snr}
loss += loss_snr + loss_l1
stats.update(stats_)
再将实验设置改回 4 卡,重新进行训练。随着第一条 loss 日志的出现,我打消了心中的疑虑,同时也暗暗庆幸我当初决定采用 L1 loss 作为备选,而不是类似 SNR 的没有数值边界的 loss,不然这个 bug 恐怕要以更加诡异隐秘的形式出现了。
揭开面纱
相信熟悉并行编程的读者此时已经猜到了这个 bug 的成因。
没错,就是 AllReduce 的通信!(对 AllReduce 不熟悉的读者可以阅读 MPI 相关部分的教程:点击此处)
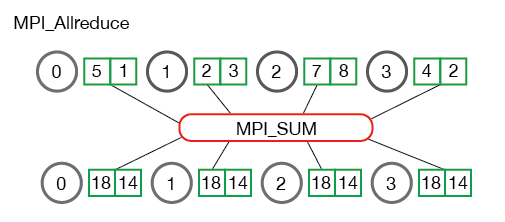
当一个 GPU 上的进程运行到 torch.distributed.all_reduce 这个语句的时候,就会向所有其他 GPU 上的进程广播它所拥有的一份数据(用于聚合),并且该进程会进入阻塞状态,直到接收到来自所有其他 GPU 上进程的一份数据,完成 reduce 的操作,才会继续运行后面的语句。
而在我修改的初版代码中隐藏的问题是,不同 GPU 上处理完一个 batch 之后得到的 stats 字典中的每个键下面的值列表长度可能是不一致的,比如
GPU 0:
stats = {
"l1_loss": [tensor(0.057)],
"snr_loss": [tensor(-1.052), tensor(-3.037), tensor(-2.041)],
}
GPU 1:
stats = {
"l1_loss": [tensor(0.044), tensor(0.023)],
"snr_loss": [tensor(-2.092), tensor(-1.899)],
}
由于不同 GPU 上所有值列表长度之和是相等的(等于 batch 数量),在运行到 recursive_average 对不同 GPU 上 stats 进行聚合时能正常完成,不会出现数据数量不一致的错误。
但是,这并不意味着聚合的过程是正确的,因为如前面所提到的,只要运行到 torch.distributed.all_reduce 这个语句,当前 GPU 上的进程就会阻塞并开始接收来自其他 GPU 上的进程的数据,但它并不关心接收到的数据是不是属于 stats 字典中同一个键的。
为了说清楚这一点,我们可以看一下 recursive_sum 这个函数的具体定义,因为在 recursive_average 中首先就调用了该函数来聚合 stats 字典中的数据:
def recursive_sum(obj, weight: torch.Tensor, distributed: bool = False):
assert weight.dim() == 1, weight.size()
if isinstance(obj, (tuple, list)):
return type(obj)(recursive_sum(v, weight, distributed) for v in obj)
elif isinstance(obj, dict):
return {k: recursive_sum(v, weight, distributed) for k, v in obj.items()}
elif isinstance(obj, torch.Tensor):
assert obj.size() == weight.size(), (obj.size(), weight.size())
obj = (obj * weight.type(obj.dtype)).sum()
if distributed:
torch.distributed.all_reduce(obj, op=ReduceOp.SUM)
return obj
elif obj is None:
return None
else:
raise ValueError(type(obj))
虽然 recursive_sum 有很多 if 分支,但可以发现,不管输入数据是哪种合法的数据类型,最终都会递归地跳转到 isinstance(obj, torch.Tensor) 的分支,并运行 torch.distributed.all_reduce 语句进行数据聚合。
以 GPU 0 上的 stats 字典的 recursive_sum 处理过程为例,它的迭代过程如下:
"""
stats = {
"l1_loss": [tensor(0.057)],
"snr_loss": [tensor(-1.052), tensor(-3.037), tensor(-2.041)],
}
"""
(1)调用 recursive_sum(stats, weight, distributed=true)
↳ 进入 isinstance(obj, dict) 分支,依次执行 (2) 和 (4)
# "l1_loss"
(2)调用 recursive_sum([tensor(0.057)], weight, distributed=true)
↳ 进入 isinstance(obj, (tuple, list)) 分支,执行 (3)
(3)调用 recursive_sum(tensor(0.057), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
# "snr_loss"
(4)调用 recursive_sum([tensor(-1.052), tensor(-3.037), tensor(-2.041)], weight, distributed=true)
↳ 进入 isinstance(obj, (tuple, list)) 分支,依次执行 (5), (6) 和 (7)
(5)调用 recursive_sum(tensor(-1.052), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
(6)调用 recursive_sum(tensor(-3.037), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
(7)调用 recursive_sum(tensor(-2.041), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
同理,GPU 1 上的 stats 字典的 recursive_sum 迭代过程如下:
"""
stats = {
"l1_loss": [tensor(0.044), tensor(0.023)],
"snr_loss": [tensor(-2.092), tensor(-1.899)],
}
"""
(1)调用 recursive_sum(stats, weight, distributed=true)
↳ 进入 isinstance(obj, dict) 分支,依次执行 (2) 和 (5)
# "l1_loss"
(2)调用 recursive_sum([tensor(0.044), tensor(0.023)], weight, distributed=true)
↳ 进入 isinstance(obj, (tuple, list)) 分支,依次执行 (3) 和 (4)
(3)调用 recursive_sum(tensor(0.044), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
(4)调用 recursive_sum(tensor(0.023), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
# "snr_loss"
(5)调用 recursive_sum([tensor(-2.092), tensor(-1.899)], weight, distributed=true)
↳ 进入 isinstance(obj, (tuple, list)) 分支,依次执行 (6) 和 (7)
(6)调用 recursive_sum(tensor(-2.092), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
(7)调用 recursive_sum(tensor(-1.899), weight, distributed=true)
↳ 进入 isinstance(obj, torch.Tensor) 分支
↳ 执行 torch.distributed.all_reduce 语句
对比两个 GPU 上的 recursive_sum 迭代过程,我们就很容易发现:
- GPU 0 在第二次执行 torch.distributed.all_reduce 语句的时候对应的数据是 "snr_loss" 的值列表中第一个元素
- GPU 1 在第二次执行 torch.distributed.all_reduce 语句的时候对应的数据是 "l1_loss" 的值列表中第二个元素
这种将属于不同 loss 的数据聚合在一起的行为显然是不合理的(“键值错位”),并且这也能解释为什么用最初修改的代码训练时,日志中显示所有 l1_loss 都是负值。
因为上述不合理的聚合过程在训练中很容易出现,并且 L1 loss 通常都是绝对值比较小的正数,而 SNR loss 则通常是绝对值比较大的负数,两者聚合在一起就很容易导致最终结果也是负数。
而在后来修改的代码中,我通过确保每个 batch 的 stats 字典中都同时保存 l1_loss 和 snr_loss 两种数据,避免了 AllReduce 的数据聚合过程出现“键值错位”的问题,也就不会遇到开头描述的那种匪夷所思的现象了。